Gricad cluster: Bigfoot#
This is the name of the GPU server of Gricad
Several nodes are accessible to you:
1. NVIDIA Tesla V100 NVLink 4 GPUs
2. Nodes with 2 NVIDIA A100
3. Grace-Hopper node with 1 chip GH200 (ARM plus GPU in HBM3e)
Here is a complete list:
chekkim@bigfoot:~$ recap.py
==================================================================================
| node | cpumodel | gpumodel | gpus | cpus | cores| mem | gpumem |MIG|
==================================================================================
|bigfoot1 | intel Gold 6130| V100 | 4 | 2 | 32 | 192 | 32 | NO |
| [ + 1 more node(s) ] |
|bigfoot3 | intel Gold 6130| V100 | 4 | 2 | 32 | 192 | 32 | NO |
|bigfoot4 | intel Gold 5218R| V100 | 4 | 2 | 40 | 192 | 32 | NO |
| [ + 1 more node(s) ] |
|bigfoot6 | intel Gold 5218R| V100 | 4 | 2 | 40 | 192 | 32 | NO |
|bigfoot7 | amd EPYC 7452| A100 | 2 | 2 | 64 | 192 | 40 | YES |
|bigfoot8 | intel Gold 5218R| V100 | 4 | 2 | 40 | 192 | 32 | NO |
|bigfoot9 | amd EPYC 7452| A100 | 2 | 2 | 64 | 192 | 40 | NO |
| [ + 2 more node(s) ] |
|bigfoot12 | amd EPYC 7452| A100 | 2 | 2 | 64 | 192 | 40 | NO |
|bigfoot-gh1| arm ARMv9| GH200 | 1 | 1 | 72 | 480 | 480 | NO |
===================================================================================
# of GPUS: 10 A100, 28 V100, 1 GH200
In order to connect , you should refer to the dahu page to create the ssh keys , the connection is the same, here are the differences:
In the file $HOME/.ssh/config :
Host bigfoot
ProxyCommand ssh -qX login_gricad@trinity.u-ga.fr nc bigfoot.u-ga.fr 22
User login_gricad
GatewayPorts yes
Warning
replace login_gricad with yours
Next, you need to set the correct rights:
chmod ugo-rwx .ssh/config
chmod u+rw .ssh/config
Warning
keep read/write rights only for the user
Then, copy the ssh keys
ssh-copy-id login_gricad@trinity.u-ga.fr
Enter the agalan passwod
then
ssh-copy-id bigfoot
Enter the agalan password
and you should be good for future sessions.
Submit a job#
You should use OAR to submit your job as mentioned for dahu cluster
The difference compared to dahu cluster is the following:
Replace gpu with cores (max 4 for nvidia V100)
#OAR -l nodes=1/gpu=1,walltime=00:10:00
Ask for the gpu model you need A100/V100,
#OAR -p gpumodel='A100'
or
#OAR -p gpumodel='V100'
or for one of them
#OAR -p gpumodel='A100' or gpumodel='V100'
Use the interactive mode
If you are developping a code, it is better to have acces to a node for debugging issues. In the passive mode, if you make a small mistake, then you have to submit your job again and wait in the queue. Using the interactive mode allows to correct your mistake and run your code until you make sure that everything is working fine.
To do that use oarsub with -I command:
oarsub -I -l nodes=1/gpu=1,walltime=01:30:00 --project sno-elmerice -p gpumodel='A100'
or
oarsub -I -l nodes=1/gpu=1,walltime=01:30:00 --project sno-elmerice -p gpumodel='V100'
or
oarsub -I -l nodes=1/gpu=1,walltime=01:30:00 --project sno-elmerice -p gpumodel="'A100' or gpumodel='V100'"
Note
There is only one node GH200 and it is experimental fro now; to use it add this, instead of gpumodel #OAR -t gh
You can also see a live usage of the gpu nodes using the “chandler” command
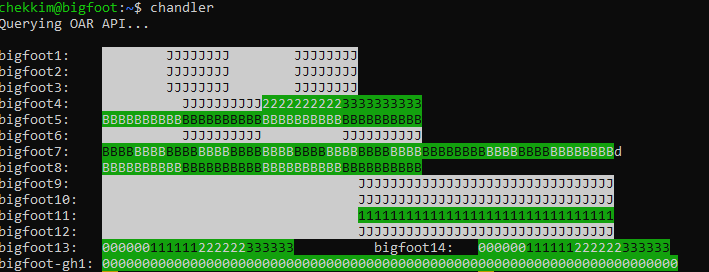
Caution
For example, bigfoot1 has 4 gpus. If you bare using 1 gpu, you will get the 1/4 of the node ressources , i.e 1/4 of the number of cpus and 1/4 of the total RAM
Make a reservation#
Mainly to avoid waiting in the queue or for a training session
In this example the reservation is made for the Grace Hopper Gh200 (only one is available)
chekkim@bigfoot:~$ oarsub -r '2025-01-20 10:40:00' -t container=testres -l /nodes=1/gpu=1,walltime=1:00:00 --project sno-elmerice -t gh
[ADMISSION RULE] Adding gpubrand=nvidia constraint by default
[ADMISSION RULE] Use -t amd if you want to use AMD GPUs
[ADMISSION RULE] Adding Grace Hopper constraint
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=2870075
Reservation mode: waiting validation...
Reservation valid --> OK
If you need to reserve more gpus at once, try A100 ou V100 models and share between users
chekkim@bigfoot:~$ oarsub -r '2025-01-26 08:00:00' -t container=testres -l /nodes=1/gpu=2,walltime=1:00:00 --project sno-elmerice -p "gpumodel='A100' or gpumodel='V100'"
Now check the status of the reservation , if it is running then ok
chekkim@bigfoot:~$ oarstat -u
Job id S User Duration System message
--------- - -------- ---------- ------------------------------------------------
2870075 R chekkim 0:07:45 R=72,W=0:59:53,J=R,P=sno-elmerice,T=container=testres|gh
Use the reservation#
Now connect directly to the node and start using the ressources
chekkim@bigfoot:~$ oarsub -I -t inner=2870075 -l /gpu=1,walltime=00:05:00 --project sno-elmerice -t gh
[ADMISSION RULE] Adding gpubrand=nvidia constraint by default
[ADMISSION RULE] Use -t amd if you want to use AMD GPUs
[ADMISSION RULE] Adding Grace Hopper constraint
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=2870114
Interactive mode: waiting...
Starting...
Connect to OAR job 2870114 via the node bigfoot-gh1
oarsh: Using systemd
chekkim@bigfoot-gh1:~$